DevLog 1: Game Engine Progress, One Month In.

A little over a month ago, I started making my own game engine, which has until now, for the most part been a learn-OpenGL-as-I-go process.
This article is the first in a series of development logs where spend time to look back and write about the past month. The intention is to document progress, decisions made, difficulties encountered and lessons learned.
It would be great if the scribblings here were of use to someone else, but for now I'll settle for giving an answer to friends and family wondering what I'm doing all day. That, and to have something to cheer me up, if I feel I'm not making progress.
The past month was devoted to
learning
1. Making choices: C++, OpenGL and SDL
First of all, I should point out that I'm not interested in taking the shortest path to "making a game". If that were the case, I'd be crazy not to go with Unity, Unreal Engine, UDK, or any other framework that solves the millions of problems that undoubtedly will arise. I'm interested in learning the technology, and the more fundamental building blocks.
1.1. Why C++
The first step is to decide which programming language to use for the
base code. This decision is heavily affected by the platform one would like
to target. For web games, you would nowadays go with
As for desktop games, any of
the above would be possible. However, if you would like to target all of the
above*, and any other gaming platform (PSP, PS3, PS4, XBox), and your top
priority is performance, there is only one choice to make:
* Maybe not web games, although there is emscripten for that.
1.2. Why OpenGL
Games need to interact with the graphics processing unit. Short of using a
game engine framework (Unity, UDK, etc), you have to deal with the graphics
card yourself. For this, there is
Linux is rapidly becoming a viable gaming platform (big thanks to
Valve), and absolutely every modern gaming platform will be able to use
1.3. Why SDL
Writing games requires window management,
It is possible to use various libraries to handle each separate aspect.
However, if you would like be cross-platform, and target Android, iOS,
Linux, Windows, Mac, there aren't that many contenders (even if you just limit yourself to desktops).
If you only target desktop platforms, you might want to consider
1.4. More decisions.
- Which OpenGL Version to Target?
The choice is to balance how old hardware to support, and what functionality is necessary.
Valve shares a survey of user hardware here. As a rule of thumb:
D3D11 = GL4 D3D10 = GL3 D3D9 = GL2
For the time being, I'm using OpenGL 4.3 while learning the technology, so as to not be limited by non-existing functionality, though I'm fairly sure I haven't used any exclusive functionality.
- Core vs Compatibility Profile?
OpenGL 3+ hid a lot of deprecated functionality in a "compatibility profile"-mode. Since I'm starting from scratch, and I have no reason to rely on this functionality, I'm sticking to the core profile. The core profile is also much, much closer to the OpenGL ES, so if you are planning to port to mobile devices, you will make it much easier for yourself.
2. Early Progress - OpenGL Basics
The first attempts at throwing something interesting on the screen.
2.5k cubes in total.
With a few minor optimizations: 40k cubes:
3. Rendering 2D, Dynamic Text
Rendering live 2D text was not as straight forward as I had
thought. Turns out that preparing images of the text to write, and then drawing
a quad with this image as a texture is a very naive and inefficient way to go
about it.
I thought it would be much worse to render a quad for each character to display, each with a screen position, and with texture coordinates for the position in a character map image. Turns out, it's not.
Just telling OpenGL is to do *anything*, is costly, much more than rendering a few hundred individual quads with individual texture lookups. This is why, instead of preparing a texture with the text to display and rendering it on a single screen (all of which takes precious CPU time), you should use a character map (an image where each character is laid out on a grid, and you know the texture coordinates of each character), and tell OpenGL how to render each character on a tiny quad, and where to place that quad.
A efficient way of doing this, I found, was to use a uniform array,
with only the necessary data: the positions in the character map texture,
and the position on the screen. Then, rendering each character as an
instanced quad (four vertex triangle strip), in batches of 256 characters
pr. render call. The optimum was found around 384 characters per batch, but
it was only 1.6% better than the nice round number of 256, so I stuck with
that. It's also a good idea to stay clear of

Btw, I'm using this bitmap font, which I didn't make.
Filling the screen with text, 32 124 characters to be exact, had a constant 923 FPS, or 1.083 milliseconds pr. frame. It's more or less meaningless to quantify it, other than to find good solutions for my own hardware. I'm happy with the solution, as it is both flexible (any font style variation is done by extending the character map) and fast. It supports TTF fonts by generating a character map with the desired style variations, including per-character width data, thus supporting variable width fonts.
4. Loading Wavefront OBJ files
Rendering cubes is boring. And writing out the vertices of something more complex, is also not worth it. It would be nice to be able to load 3D meshes, with texture coordinates, and normals. One of the simplest and most widely supported formats is Wavefront OBJ.
Writing a parser isn't very hard, but certainly tedious, so I used
4.1. Speeding it up 50-100x
The main draw-back with the OBJ format is that it is a clear-text format. The data is written in ASCII characters, and needs to be parsed. This actually takes a significant amount of time. E.g. the Rungholt scene takes around 38 seconds to parse.
A simple workaround is to write your own binary format that handles the data you are interested in. This is surprisingly quick to do, taking only two hours to implement. It reduced the Rungholt load time from 38 to 0.7 seconds.
Here are the 70 lines of code, for both writing and reading to
the
5. Deferred Rendering
Deferred Shading is one of the methods I read about, and was awed by, thinking it would be hard to implement. Turns out yet again that it wasn't, at least the basic functionality. Then again, I haven't gotten to the hard parts yet (lighting, shadows, not to mention transparency, so these words might mock me later.
In traditional forward rendering, the geometry goes through the rendering pipeline, performing all computations necessary to determine the end result, as a pixel on the screen. If it turns out it ends up behind something already on the screen, and throws it away, along with the effort to compute its values.
The main idea with deferred shading is to store the minimum necessary data to compute the output image, as textures. Then, draw a quad filling the screen, and with access to the "data textures", compute the output image. This very neatly splits the process of preparing the data for rendering, and performing the heavy computations (i.e. deferring the heavy work to this second stage, hence the name). It also allows for some very cool screen space effects, which I will get to soon.
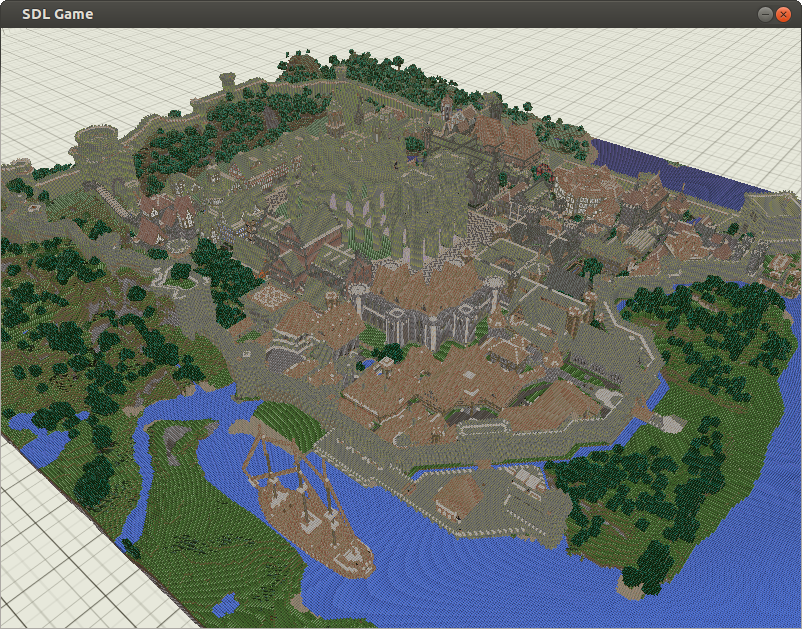
Currently, only position, normals and albedo texture is stored.
Position

Normals

Albedo texture
Z-component of position (adjusted)
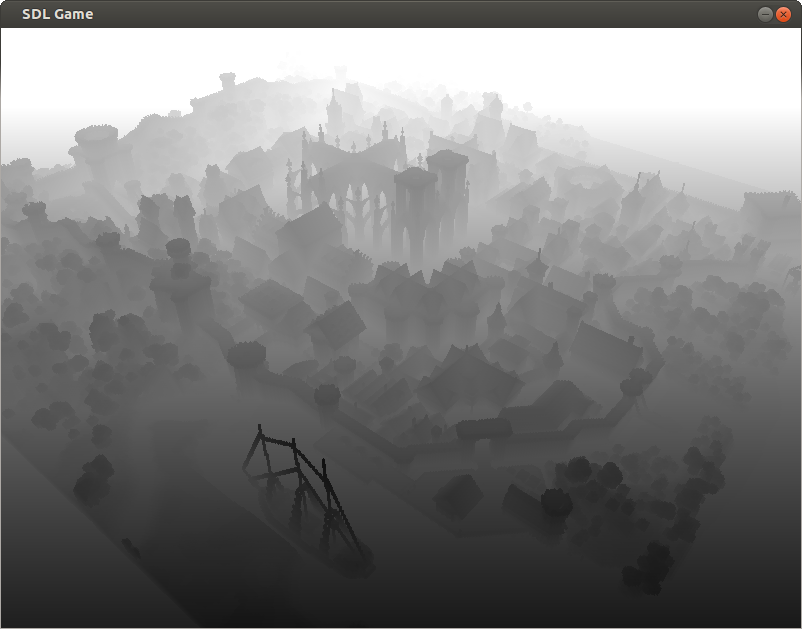
Since it might not be apparent from the position data image, that the depth buffer is contained there, I added a visualization of just the the z-component (with adjusted ranges for better visualization)
Retrieving the data is done through texture lookups.
5.1. Diffuse Shading
For a diffuse shader, all that is required is normals normals and positions data.
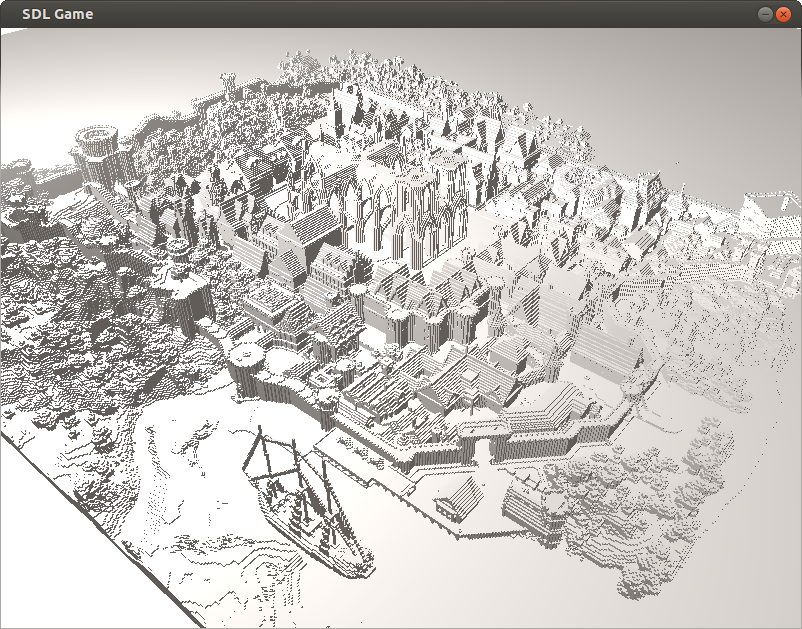
Diffuse shader
5.2. Edge Detection
Using a Sobel operator on the depth data, a visualization of sudden depth changes can be achieved.

Depth-based Sobel edge detection.
5.3. Screen Space Ambient Occlusion
Screen space ambient occlusion (SSAO) is a clever technique to approximate the shadows that would result from geometry occluding global illumination. The implemented method is quite basic, with random sampling, but no blurring.

Screen space ambient occlusion (SSAO) + Sobel edges
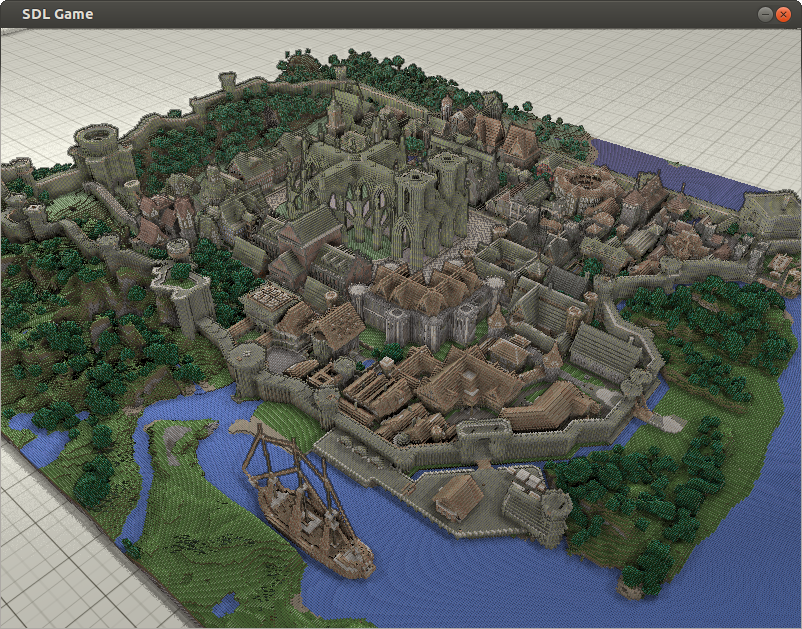
5.4. Putting it together + gamma correction
Combining the above effects:
- Texture color
- Diffuse shading
- Depth based edge detection
- SSAO
- Gamma correction
YouTube video. The framerate is a bit low, but it's mainly because of the amount of geometry.
6. Shadowing OpenGL State
Telling OpenGL to transition to a state that it's already in, changes nothing, but might still be an expensive call, and it's recommended to avoid it.
The easiest way to do so, is shadowing (aka mirroring) the
6.1. Finding Redundant State Changes
Below is a
screenshot, showing two functions I've yet to add to my GlState
shadowing:
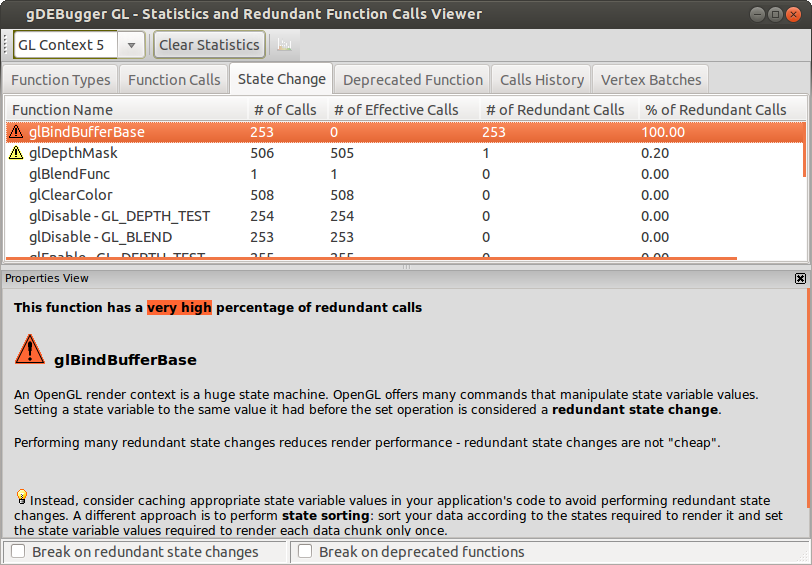
6.2. Is it worth it?
For learning OpenGL, definitely. It helps to understand the OpenGL state machine. However, as for performance concerns, there was no gain in avoiding redundant state changes, if anything a slight penalty due to the added overhead. It might be a different case once the rendering complexity becomes more realistic. Since it's easy to implement, and easy to disable once you do, I'm still happy to have it in place.
The second alternative which might be better for performance, but a lot trickier to implement, is to sort operations based on state, and executing them in the order with minimal state change. With this you don't only avoid redundant state change request, but actually avoid the redundant state change altogether.
7. Other Stuff
I fear this article is getting a bit out of hand, and I might end up spending far too much time on it. I'll try to just summarize the rest.
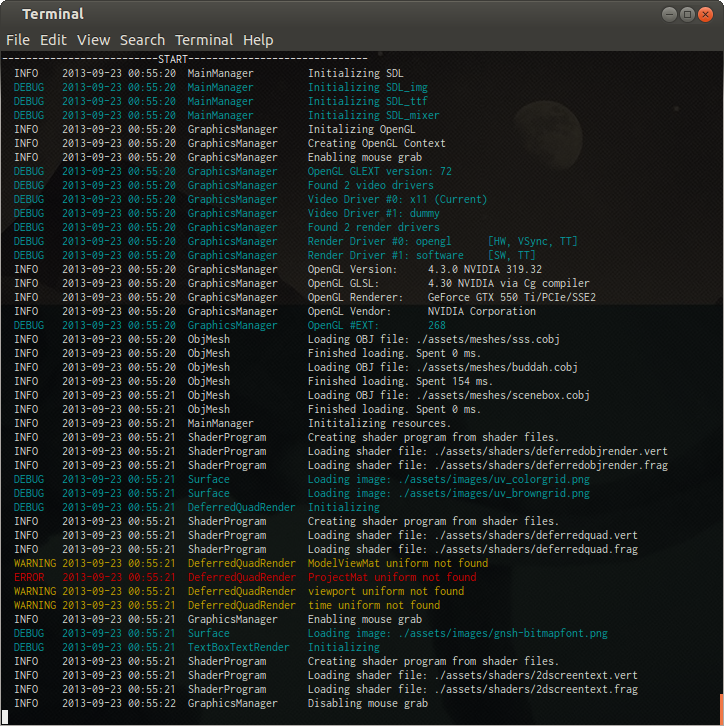
7.1. Logging System
Using
- Level system (debug, info, warning, error).
- Timestamp.
- Log instance owner (who made the log entry).
- Storing log output to log-file.
- Ability to define a macro, to compile away logging.
- Various colored terminal output styles (currently only
bash ).
7.2. Automatic Shader Rebuild
When learning GLSL, it is nice to minimize the time between changing shader code, and seeing visual change. For this, automatic monitoring of files is performed. When a file's timestamp is newer, it reloads the file, compiles and links the shaders. If it succeeds, the current shader is replaced. If it fails, it rejects the current modification and keeps the existing one, logging error output.
Here is a quick demo:
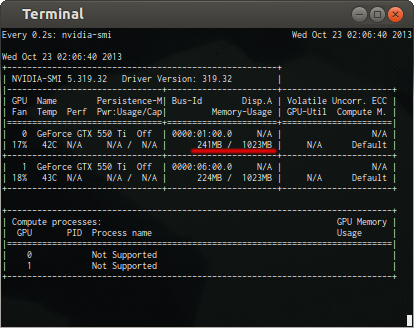
7.3. Checking for OpenGL memory leaks
Since I'm using an nvidia card, and linux, the utility
7.4. Unit testing
If used right, Unit testing can be an invaluable tool. It can help the class design process, catch bugs early, document functionality, and later let you be confident that a change you introduced didn't mess up something else.
My favorite unit test system (by far) is
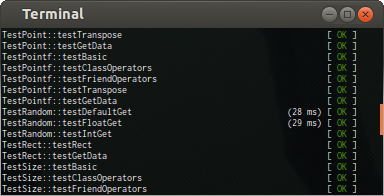
Here is an animated gif showing how simple it is to add a test suite, and individual test functions.
{kind=link}
7.5. Automatic Build System
See my previous article on the setup for automatic code compilation. It saves a ton of time, however, it might not be viable for large code bases.
8. Thoughts & Conclusions
I spent too much time writing this.
If you want the source code, let me know, and I'll consider putting it on github. Currently, it's hosted on bitbucket.
Table of Contents
Top 1. Making choices: C++, OpenGL and SDL 2. Early Progress - OpenGL Basics 3. Rendering 2D, Dynamic Text 4. Loading Wavefront OBJ files 5. Deferred Rendering 6. Shadowing OpenGL State 7. Other Stuff 7.1. Logging System 7.2. Automatic Shader Rebuild 7.3. Checking for OpenGL memory leaks 7.4. Unit testing 7.5. Automatic Build System 8. Thoughts & Conclusions
Tags
OpenGL GLSL SDL2 devlog gamedev
License

About
Roald Fernandez
Norwegian software developer
Thinks alpacas are underrated
Newsletter
